Service Worker Development Best Practices

Last Updated -

After developing about 100 progressive web applications, production and example over the past few years I have come to realize there are good ways and bad ways to develop service workers.
You will learn common road blocks that trip developers when they start creating service workers and how to bypass them. You will also learn some strategies to incorporate higher quality service workers in your applications.
Today I am going to share several best practices I have learned or incorporated over the past few years to improve my developer experience and service worker quality.
Since most websites don't currently use a service worker and most that do have not done a good job I hope this serves as a good reference to start your PWA journey or improve your current implementation.
Today I am going to share things I have learned to make my service worker development more productive and produce even better quality service workers in the end.
Some of these tips relate to how to use the browser development tools more efficiently. Others relate to actual coding. Finally there are tooling settings you will want to know how to set.
Finally I plan on making this a living document. As I started writing I began with 5 practices and I added more. So I will add and update this document from time to time, so add this to your favorites list and be sure to subscribe to email or push notifications so you will know when the list is updated.
Let's get started!
Disable the Service Worker for Normal Development
If you are working on your actual user interface (UI) you should bypass the service worker. If you don't you will drive yourself nuts and waste lots of time.
Of course the primary reason we use service workers is to cache network responses, which means when you are updating website assets you want the latest version to test and verify. If you have CSS or JavaScript files cached the browser will load the cached responses, not the version you just modified and saved.
There are two ways to turn the service worker off, well actually three.
The easiest way to load from your local web server is to perform a hard reload. Each browser allows you to do this, typically by pressing Ctrl + F5. Mobile browsers force you to do a little more digging, but you can do hard reloads on your phone as well.
The service worker specification requires browsers to support this feature specifically to help developers troubleshoot issues. It also gives end users an out to bypass a potential bug in your service worker, but it is really meant for developers.
The next way to bypass the service worker it to literally bypass the service worker.
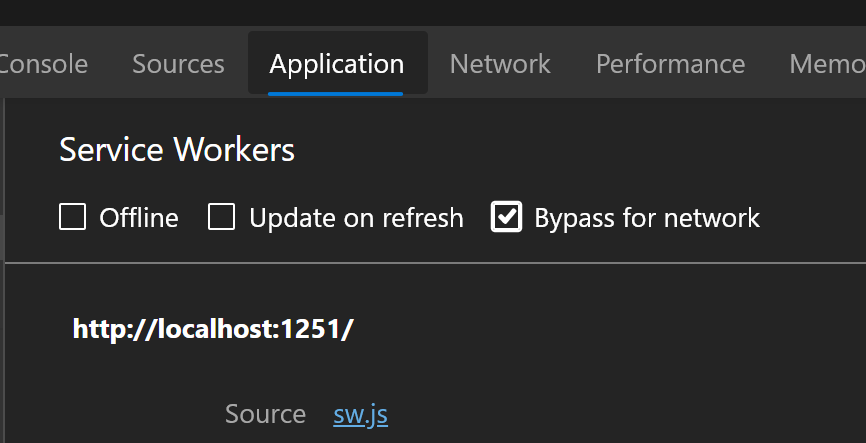
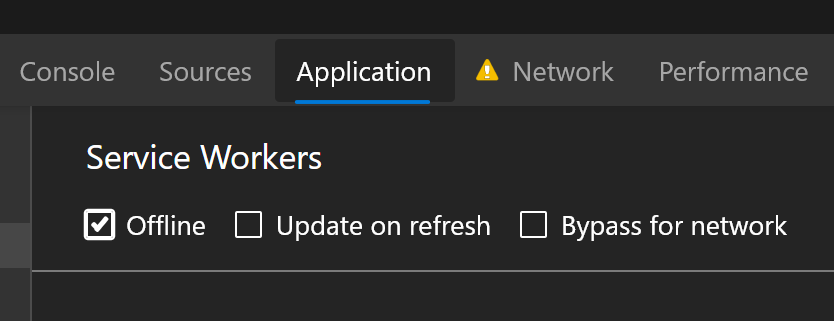
If you are actively developing and updating, you most likely have the browser's developer tools open. In the Application tab there is the service worker sub-tab. Along the top of the service worker panel are a series of toggle to turn on and off different features affecting your service worker.
One of these toggles the service worker. I recommend developers bypass the service worker using this toggle while working on the front-end. Just don't forget to turn the service worker back on when you are ready to deploy.
You must test the website with the service worker before you accidentally commit a bug.
A final, very drastic move is to unregister the service worker in the dev tools and then comment out the service worker registration code. I don't recommend this technique because many of us will forget to uncomment the registration code.
No matter what option you choose make sure you test with the actual service worker before committing your updates.
Have a Real Development Web Server to Test on Mobile Devices
Let's face it the online world is mobile, not desktop.
Development takes place on the desktop. We have developer tool features to help us debug layout issues, but there is nothing like a real phone to verify, especially an iPhone.
You can open a hole to your localhost web server, but honestly this can be a pain for many reasons.
Instead I prefer to go to a real, live environment I can access from any device. For me this is very easy since I build progressive web applications using an AWS serverless backend using static web pages.
Since I use AWS and a CloudFront distribution I don't even have to configure a custom domain. CloudFront gives you an abstracted domain with HTTPS. You can then enter that domain on your phone or phone test device and see how it works for a real user.
You will need one or more test devices. I use an Android for my personal device, which provides me a solid test device for most of the world.
But most business stakeholders, at least those inquiring with me want to make sure their PWA works on iPhones. So I also have an iPhone. Unfortunately it is an iPhone 6, which just got deprecated by Apple, so I will be updating to an iPhone 8 or 9 sometime soon.
I won’t sugar coat it iPhones are very expensive, even used. I can get 4 or 5 Android test phones for the price of one iPhone.
Fortunately there are different places to buy a used iPhone. I purchase mine from Amazon. Unless you want to pay for a monthly cellular service subscription you should buy an unlocked phone.
Apple does have a crazy policy that requires you have a SIM card in the phone to use it. The SIM card does not need to be active. I found I can buy them from my local AT&T store for $25. Androids do not require a SIM to function, another advantage.
Personally I have about 10 devices, but many of them are starting to show their age. The good news is tablets are really starting to die out, which means you don't need to worry about them as much as I did in the past.
Don't Use localStorage to Persist Data
I love localStorage, have for a long time. It is a great place to persist data between user sessions. I even used it to cache website assets for controlled access much like how the service worker cache functions today.
There are two problems with localStorage, size and access limitations.
localStorage is typically limited to 5-10MB of data and must be a string. It is a simple storage medium, which is what makes it attractive and honestly you can store quite a bit of data in localStorage before hitting a quota.
But you can't cache photos or videos like you can the service worker cache or IndexedDB (IDB). With cache and IDB you can persist several gigabytes of data, even on iOS.
Despite the quota limitation the real issue is localStorage is not accessible in the service worker. The localStorage API is synchronous. Every API in a service worker must be asyncronous, or based on a Promise.
Since localStorage is not accessible in the service worker it limits the service's usefulness.
Instead use IndexedDB. Don't worry about programming directly against the native API, it is complex. Instead use an abstraction library. Personally I use localForage, a library that provide an API that mirrors the localStorage API, but with promises and of course it stores the data in IDB.
By relying on IndexedDB you now have a large database to cache just about any type of data which is accessible to both the UI and the service worker.
And yes you can store photos and videos in IDB!
Disable Browser Extensions
From time to time the browser developer tool debugger seems to go haywire. This can cause hours of lost time trying to step through the code.
Something I found recently is some browser extensions seem to inject themselves in the service worker pipeline. What I noticed was in the console tab the extension was being referenced, not the service worker or the top level.
The console reference was the clue I found that helped me get around the issue. The real issue I was had was in the code debugger. The service worker script was not being loading correctly. At least that is the best way I can describe it.
This mean my breakpoints were not being hit and I could not debug the script.
I have no idea why the extension was interfering with the debugger, but I realized disabling extensions the issue went away.
So while we let Microsoft and Google fix the developer tools this does fix the issue.
Do Not Use Hot Reload
This is bigger than you think.
I don't normally use a hot reload solution for local development. But when I do it makes a mess of things, even when I am not doing service worker work.
I have noticed hot reload solutions tend to crash when the development tools are open, which makes for a mess when you are in the middle of trouble shooting an issue.
But the real issue I have encountered is toggling between my development environment and the developer tools is the service worker saving, which triggers the hot reload.
If I am reviewing network requests this makes for a frustrating and tedious process as the network waterfall clears and refills, often not in the state I need it. Now I have to go back through a series of steps in the UI to recreate network requests, etc.
Not only does this create frustation for me, the developer, it slows down the development process and that frustrates stakeholders.
How hard is it to press F5 when you need a real page reload? Just do it that way.
Pro Tip: You can map your development environment or folder in the developer tools. Now when you update a script or CSS rule in the developer tools the changes are saved, so you don't need to toggle back to your development environment at all!
You Need to Know All Network Requests
This is something I find most developers and architects don't plan or know, which is how a page loads assets and updates data through an API.
You really should know every network request made and create a service worker strategy to handle the request.
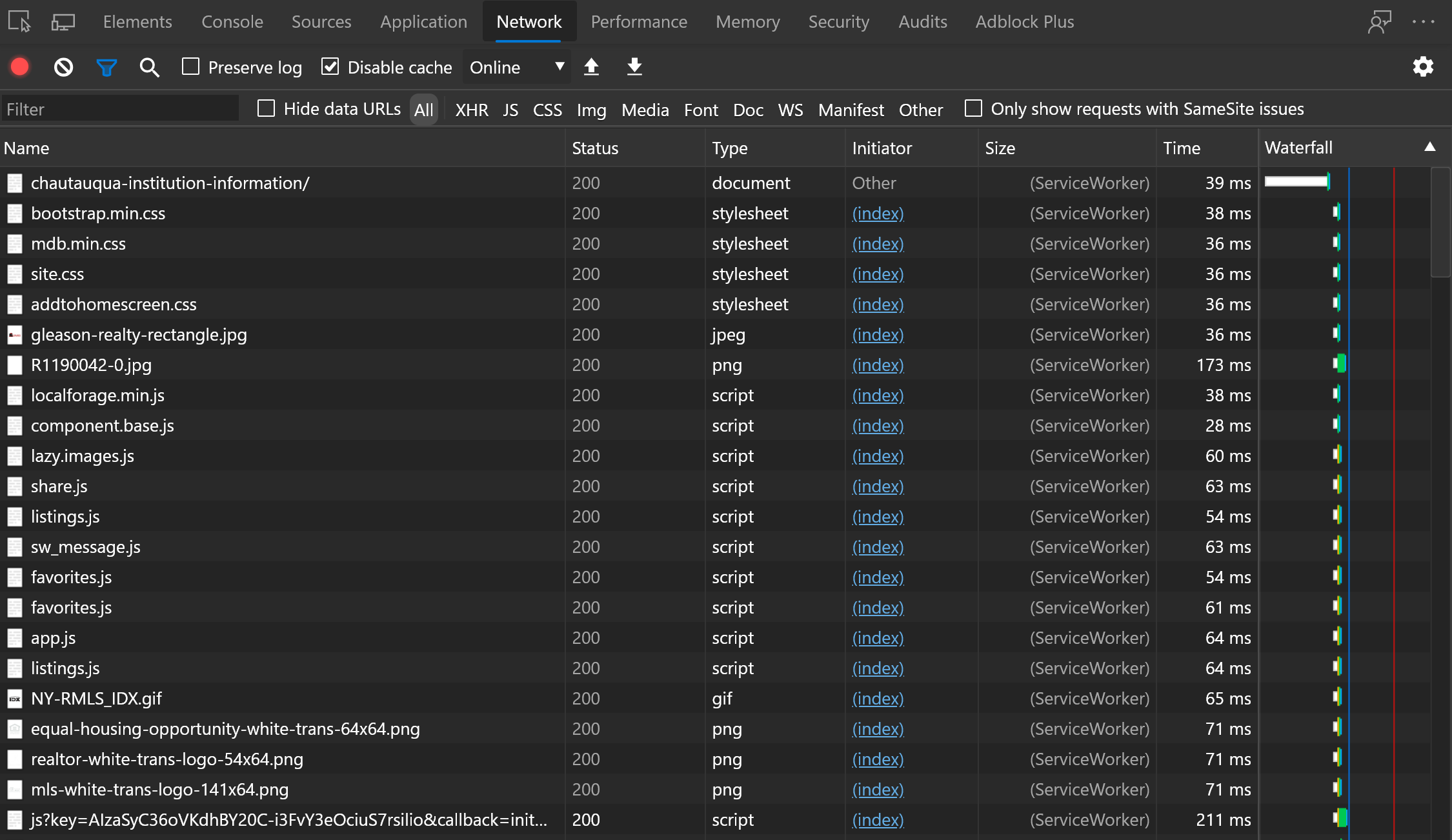
The service worker strategy includes how you cache responses, how long they are cached and what triggers an invalidation.
You also might want to intercept outgoing requests (PUT, POST, DELETE) and modify or even cache the request data.
It is surprising how many site owners don't know how many or what types of requests their site makes. This can lead to page rendering delays even if you are not caching the asset.
The final issue you will encounter is when the device goes offline you most likely will have a mission ciritical network requests you did not realize your page needs.
By knowing and mapping all your network requests you will know how your application really works and make sure it works even when the network doesn't.
Always Define an Offline Response
Another common oversight is not handling an offline state for every network request. You need to know all your network requests 😎.
Remember there are all sorts of network requests, which means you need to know what type of request is being made. This is at least two-fold.
What is the request being made for, or what is the purpose of the request. Is it for the page document (HTML), image, CSS, JavaScript or other media?
Next know how that request is used. For example, just because it is an image does not mean you should just return a single offline image for all requests. If the image is a product image in a catalog then you should return a context appropriate photo. For other images you might be able to get away with a simple transparent placeholder.
Just don't return a 404, which triggers that ugly empty image display on your page.
Images are a good segway to the next discriminating factor, the mime-type. If you don't know how to determine or use mime-types you really need to understand this to be a good web developer.
Each image type has a unique mime-type, as do scripts and CSS files. Do not just apply a generic mime-type to images, this is bad practice for many reasons. Browsers are pretty good at guessing, but don't make them work harder than they already do.
Scripts, for example are 'application/javascript', not 'text/plain'. In fact you can't register a service worker if the mime-type is not properly set. Sometimes browsers won't process the script if the right mime type is not applied.
Within the service worker you can inspect the response to see the mime-type. The content-type is accessible via the response.headers["Content-Type"] property.
Now you can use that value to trigger a workflow to handle the response appropriately.
its important to use the Content-Type and not the file name to determine file type. While file extensions can provide an insight into the file type, it is not reliable. Just think about extensionless URLs, no file extension to interrogate.
Assume iOS Cache Restrictions
When doing web development always assume the least capable environment is where your application will be rendered. Today that means Apple browsers, specifically iPhone Safari.
Apple limits service worker cache capacity to around 50MB. This freaks many out when they read this because they assume they can't cache their application.
So here's the secret, don't cache binary assets in service worker cache.
50 MB is way more than any website really needs for its web assets. This includes HTML, CSS, JavaScript, some common issues and fonts. You can even cache JSON data, it is it not too large.
For example, Amazon should not cache it's product database in the browser. So be selective if you need to cache lots of data.
Instead lean on IndexedDB. As I stated earlier allows you to persist gigabytes of data, even on iOS.
You can store binary files, like photos and videos in IDB, so feel free to store them for offline access.
The trick is to capture requests for these assets and then create a response on the fly by fetching the cached data from IDB and supplying that to your custom response object.
To do this, get the response body through the blob() helper method. This will give you the binary body bits, which you can save to IDB. localForage will handle this for you. Here is an example:
return response.blob() .then( data => { return { "body": data, "url": imageURL }; } );You will still want to apply proper cache invalidation rules just like you would for service worker cache.
Host Assets on Your Site's Origin
CORS sucks.
I waste hours and hours of time working through CORS issues with my sites and my client's sites.
CORS was designed to allow cross origin URL access from the browser. The reason why the method exists is to provide a 'safe' way to allow access to third party origin assets. I won’t get into why cross-origin access can be a security risk, just know there are logical reasons why CORS exists.

At the same time is a giant pain to work with, especially when it comes to managing third party requests in a service worker.
You must properly configure your server to return cross-origin response headers. For every server environment this needs to be handled differently, so I won’t bother showing how to configure CORS headers.
What I will show is what a standard set of CORS headers look like so you know what to inspect for.

When making a fetch request you will want to set the method to 'cors'.
You can test a URL to see if CORS headers are properly set in Postman. Sometimes you wont be able to properly inspect improperly configured URLs in the browser tools, so Postman is a must have tool to visualize network requests.
The easiest way to avoid CORS of course is to host your assets on your site's domain or origin. By doing this you do not make a cross origin request. APIs can be tricky in this regard but assets like scripts, CSS and images should all be hosted under your origin.
You Can Develop a Small Scale Web Server
I do this all the time, especially for small sites. I design the service worker to cache all the pages or at least the common page assets and a rendering engine to build the pages as they are needed.
I can often cache the site's data (again not for you Amazon), header, footer and page templates in service worker cache. I then render the pages ahead of time or on demand. This eliminates the need to have a network connection.
A recent public example would be the PubCon application I shared back in October. The entire schedule and speaker bios are available offline because the initial page request registers the service work which immediately renders the entire site and caches it for quick access.
But even if I did not render everything up front, it could trigger the rendering engine to create a response on the fly. I did this early on, before I got the confidence to render all the pages in a site.
If you are worried most sites can be pre-rendered an require only a few KB of storage, so you have plenty of room to pre-render most sites.
Don't Try to Recreate All Your Business Logic in the Service Worker
This problem is far too common, mostly with single page applications.
Applications require a lot of business logic, but the majority of it should reside in the cloud, or below the water line in my illustration.
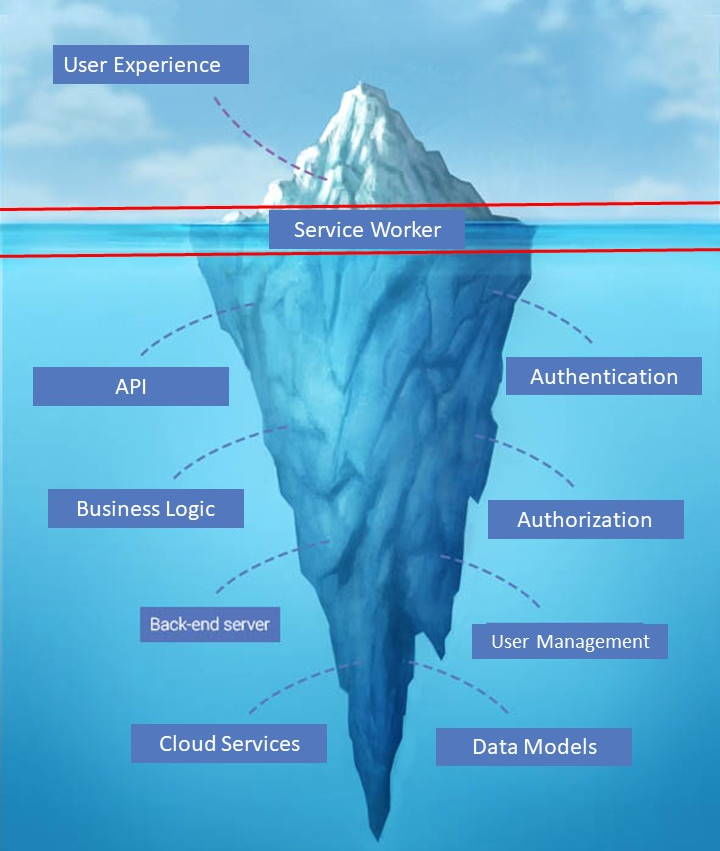
As you can see the business logic composes most of the application profile. The client side or UI is very thin.
Unfortunately, the rise of single page applications or really the abuse of this architecture has served as an excuse for developers to try and duplicate an entire, complex business logic layer in the UI.
I won’t expand on all the reasons this is a bad idea.
Instead you should focus on the web client implementing what I have started calling UX triage business logic. It should focus on making sure the user has a smooth experience, not apply lots of complex business logic and frustrating delays.
Think about it this way, not only are you exponentially increasing your development time and responsibilities by duplicating the coded base. Testing requires verifying the code in multiple environments, most of which you do not control.
This means lots of things can and will go wrong and you are on the hook for dealing with them.
Plus any hacker will analyze your application to see how requests are posted to the server and can quickly create a script to attempt the things you are trying to block.
You are better off relying on your controlled, server or cloud environment to verify and validate data as the single source of truth before committing it to your database.
It can be tempting to build more business logic in the service worker, I mean it functions on a separate thread and does not block the UI.
But this is not a good idea. Instead you should build enough logic in the service worker to make sure any cached data is in a UI usable form.
This may seem to contrast to my suggestion to use the service worker as a small web server, but it does not. The web server concept is more about rendering markup and not about business logic. These are distinct concepts.
Summary
Service worker development is not simple by any means, at least if you create a service worker that adds real value to a website.
These are some common best practices I have noticed developing many PWAs how these practices can help your development processes and deliver a better user experience.
I hope this helps you on your PWA journey!