
Lessons To Learn From the SBA E-Tran Website Crash - How the Cloud and PWAs Can Help You Scale

Last Updated -

Social distancing has created unprecedented demand for online government systems.
The government ordered business shutdown led to compensation promises through the small business administration (SBA).
But their antiquated systems could not handle the demand spike.
This left many frustrated: banks, business owners, individuals and even congress.
Not to mention the overworked folks at the SBA and other government agencies.
The programs are meant to help closed businesses and individuals survive. They don't help when they go down.
Let's salvage something from this experience so you wont suffer the same fait as the SBA.
So how do you fix a website crash?
The first step is knowing how a website can crash and what makes a website crash.
I am going to answer these questions and more examining the government platform failures.
Beyond why these platforms are struggling I will show how the cloud can solve many of these problems.
I will also share how progressive web applications can help reduce server demand. This can reduce the amount of server resources and costs to run applications.
In the case of the government problems, how do you prevent a website crash from increased traffic?
Part of the blame is due to what I call software entropy, or the natural decay of software overtime. Without regular attention or energy, systems become inoperable.
This was the main point I made in my recent article on why jQuery is obsolete and the discussion on DotNetRocks about the same topic.
Anytime we watch systems fail like these have there are lessons to learn. You can apply these lessons to your business as well as the government.
Why The SBA and Many State Unemployment Servers Crashed
The problem, most government platforms still rely on 70's and 80's technology. Even the more 'modern' government systems use technology from the early to mid-2000's.
And while 10-15 year old platforms may not sound old, they are.
This has lead to many states and federal government platforms to crumble from demand.
Government platforms are not the only platforms that crash under demand spikes. Businesses of all sizes have experienced similar issues.
A few years ago 84 Lumber spent millions on a Super Bowl ad campaign. Their website failed even before the commercials aired.
In today's cloud first world there is no reason any website or server platform should not scale. Even when that demand is millions a second.
Cloud platforms like AWS, Azure and others are designed with demand spikes and distribution in mind. Most government platforms are still limited to physical servers and AS400 (mainframe relics of the 70s and 80s).
The system cracks were exposed when the US was placed under quarantine. Different state unemployment systems could not handle the demand. The SBA had similar struggles, but more due to lack of funding.
On Monday April 27, 2020 the SBA reopened their E-Tran platform. This allowed certified lenders to submit new applications for the payroll protection program.
But it could not handle the demand. It locked up and became unresponsive.
"We have been attempting to access E-Tran since 10:30 and have had no luck," said Maria Amoruso, chief marketing officer at Pennsylvania's NexTier Bank, told NPR.
She needed to submit just 13 loan applications. By lunch they were only able to submit a single application.
They were not alone.
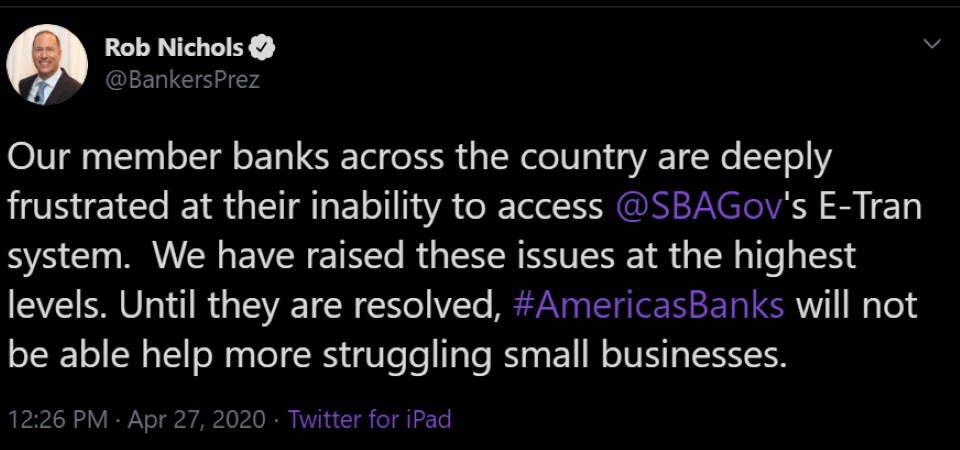
https://twitter.com/BankersPrez/status/1254809202222075904
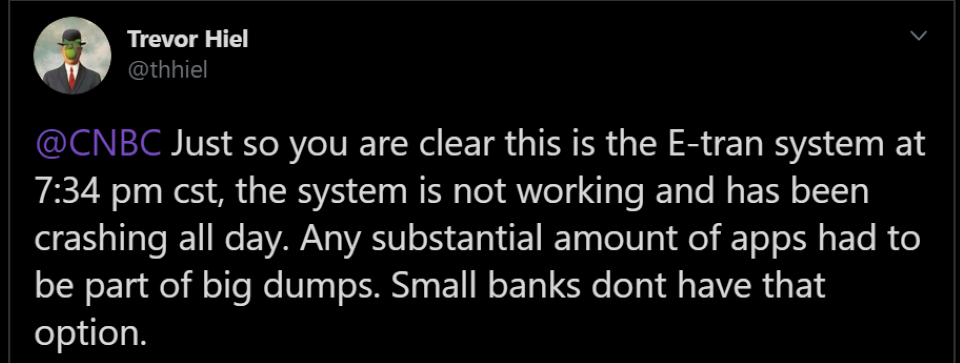
https://twitter.com/thhiel/status/1254932330076135426
As I understand the SBA E-Tran system there are two interfaces: a website portal and a direct API.
Small banks like NextTier are relegated to the web portal. They do not have the volume to justify hiring someone like me to build an integration to the SBA API.
But the SBA web portal is a human interface to the API, where the real demand is met. The website needs to be able to handle the demand from the thousands of small lenders.
The website is an added layer or possible point of failure.
The SBA contracted with a company in Baltimore to build the web portal. The web portal was created in less than 10 days, which honestly for a simple form like the Paycheck Protection Program required is more than enough.
But the underlying platform was the weak link.
The API is used by larger banks and lenders. They have developers on hand that can integrate their systems with the SBA. This is why there are so many banks with online forms to collect the data and documents required for the PPP loans.
Larger institutions submit bulk applications. Think several thousand. Many were in a queue from the previous funding round.
I have a unique opportunity into how E-Tran works. I have a friend that works for one of these banks doing the SBA integration.
The API was not designed well, even by 2000 era standards, sorry. This lead to banks having to test against the production or live platform. The API was not documented and error messages were very generic.
This created even more congestion. Integrators were forced to just try and see if the call worked.
For the record the SBA is not alone, I have dealt with similar APIs at an alarming rate in the past few years.
I feel for the Small Business Administration. They were not prepared. Their technology is fragile and outdated and understaffed for the spike. They did not have enough money on hand to handle the demand.
Politics aside, this is common in and out of government.
This has created a horrible atmosphere in the agency.
While I cannot offer a solution to the funding issues I can offer insight and advice to the technology issues. Improving the technology would also reduce the burden on the overworked staff as well.
Instead of 75+ minute hold times to speak to an SBA representative. Business owners could access their account to track statuses for EIDL and PPP loans.
The age of government servers, both hardware and software is an obvious cause of the problem. But there are many reasons why an online system can go down.
Why Websites Crash or Go Down Under High Demand
There are many reasons why a site or server may become unresponsive, even without high demand.
Hacker Attacks
After demand spikes the next logical target is hackers and viruses. There are different ways these attacks can bring a system down.
First, many hackers are trying to overwhelm the system with high demand. This is known as DDoS, or Distributed Denial of Service attack.
Sometimes this is intended to trigger reboots or vulnerable states as the system tries to recover. Other times it is meant to take competition offline.
Either way it is bad.
The good news is most DDoS attacks can be thwarted with modern cloud platforms. This is a reason why using a good content delivery service is recommended.
Viruses and other attacks are meant to get behind the firewall and either take control or destroy the system.
Again there are many common ways to guard against this sort of attack. You should always have a good security policy and staff in charge of your system.
Attacks are more of a security issue and a bit beyond the scope of this article. Organizations should not discount their importance. Have a good security policy in place. Understand your platform's security model and take precautions to guard against unwanted intrusions.
Bad Code
Errors in code happen. I am guilty of this all the time. I test and test, then deploy and something somewhere broke.
I do my best, as do most developers, to correct those issues as quickly as possible.
However, many times errors persist. These errors cause workflows to stop or worse systems to lock up.
You can open browser developer tools (F12) on most websites and see at least one logged error. This is a simple example of the problem.
Bad code can also create memory leaks. Over time these leaks cause the server to stop working as there is no more room to work.
In a perfect world you will have a good error reporting system in place. Unfortunately, developers are faced with cryptic error messages from platform and third party dependencies.
This can make troubleshooting issues frustrating at best.
Bad Architecture
As a dovetail to bad coding practices is the overall system architecture.
If you rely on a giant monolith with hard dependencies you are asking for crashes. You are limited by your weakest point.
In a serverless, cloud based platform you rely on a distributed workflow. Generally modern systems are based on messages between tasks to trigger processing.
This distribution allows various parts of the system to scale as needed. It also frees your user interface, whether a website portal or API to respond to the user faster. Processing continues in the back end.
One of the reasons why many website applications lock up or crash is the server is tied up waiting for backend workflows to complete.
Instead you should post data from the client to the backend and return quickly. Let the user know you will notify when a long running task completes. There are many ways to do this, such as web sockets, push notifications, email and even SMS.
Believe it or not clients have asked me to fix applications with 13.5 minute wait times! The problem is more common that you realize.
The good news is good architecture can solve a lot of common user interface bottlenecks.
Hard Disk Trashing
This is usually a symptom of bad code and or bad architecture. Servers, even the cloud still rely on hard disks.
Even though we have migrated away from spinning disks in favor or solid state drives (SSD) thrashing is still a problem. Many enterprise and government servers have not been upgraded in a decade or more. This means they still use platter based drives.
I wrote about this issue in detail in an article about why you should have a favicon.
A well designed website or API should avoid accessing the hard drive as much as possible. This means you want to cache content and data in memory as much as possible.
Accessing memory is much faster than access the disk, even when it is an SSD.
I will discuss later why progressive web applications help alleviate disk access.
Infrastructure Dependencies or How the Cloud Prevent Website Crashes
When the Internet was born we ran servers (websites, Archie, Gopher, databases, etc) from physical boxes. Typically they were running under someone's desk or in a closet somewhere.
Over time we migrated to formal data centers and racks. I used to have 3 rack servers and paid through the nose to have them in a nice data center I could visit.
In the mid to late 2000s we started migrated to virtual servers. Today we have serverless.
That is not to say there is no server, but the concept of a box or virtual machine is out of date. Even containers seem old school to me.
Today I build systems relying on a series of connected cloud based services in AWS. At the heart of the applications are lambdas.
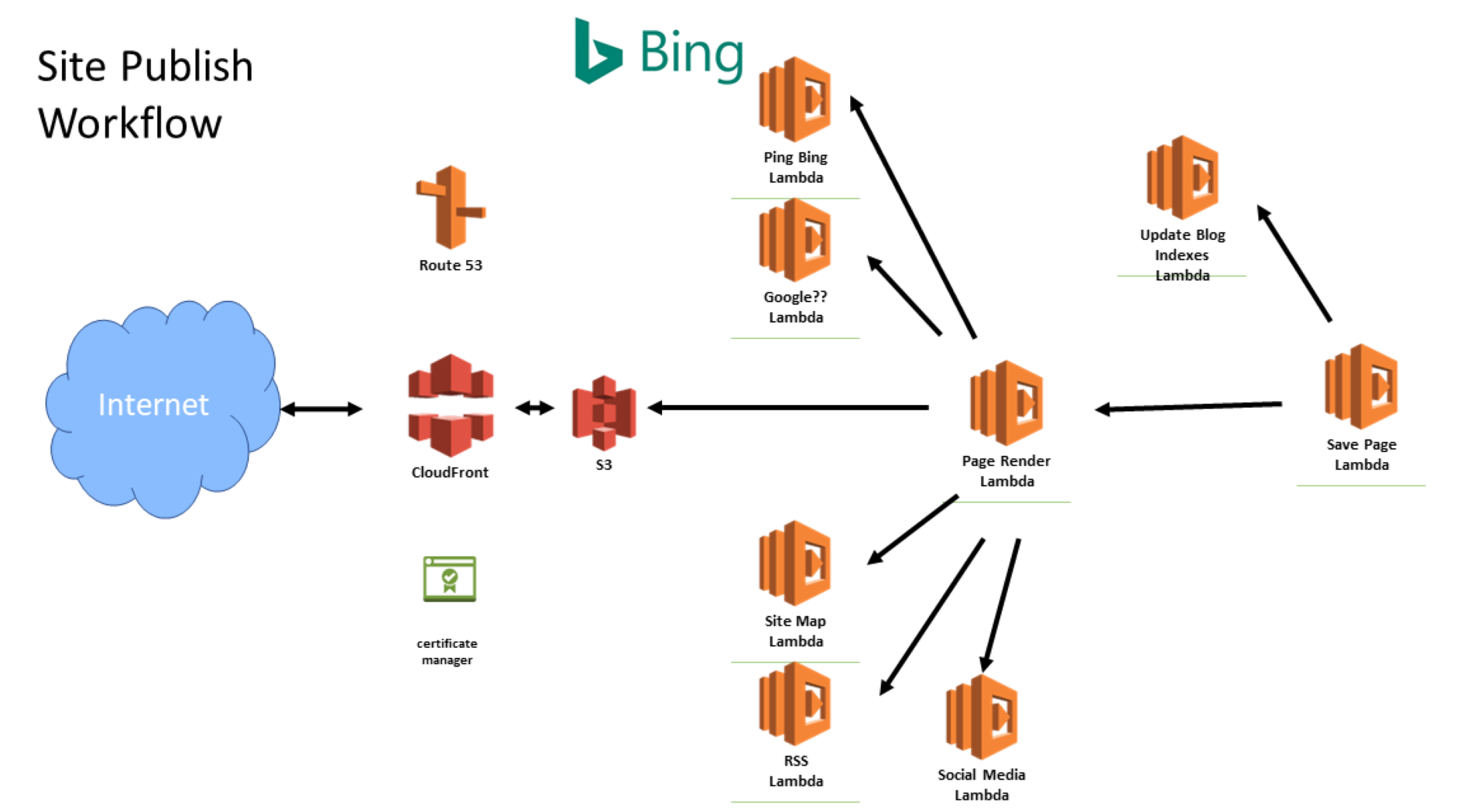
These are small, dedicated hosted functions. I trigger them through the API, messages or a few other mechanisms to process 'data'.
The nice thing is I do not need to maintain an actual server. I am not limited to the capabilities of that physical box. Even if it is virtual. If I have a demand spike, AWS creates new lambda instances to meet the demand in real-time.
The cost is attractive as well. For the monthly price I paid 15 years ago to host those 3 boxes I can now have 9-10 months of AWS hosting with more features!
And did I mention, the application just scales? I don't have to do anything special, it meets demand as it increases.
So if you are still working from a physical or virtual server you should look to upgrade soon.
This is actually a key reason why the Massachusetts department of unemployment was able to meet recent demand. On the other side, New Jersey fell flat as their AS400 based system crumbled with a simple nudge.
Expired Domains
I threw this one in even though it may not cause a perceived crash directly. Expired domains are common.
I have registered and managed hundreds of domains for clients over the past 3 decades. Despite numerous notices and invoices I cannot tell you how often domains are allowed to expire.
This not only takes your website down, but other branded services like email. It can bring your business to a stand still.
You may also have a third party dependency. If they let the domain expire your system will most likely break as well.
So stay on top of your domain renewals. You can register/renew a domain for up to 10 years for most top level domains (.com for example).
How Progressive Web Applications Can Help Prevent Website Crashes
Service workers allow you to cache website assets and data on the client. Since these resources are accessed locally demand for server or cloud resources is reduced.
Yes, it is that simple...sort of.
I have covered the basics of how service worker caching works in another article.
For a quick primer, the service worker runs in a layer between the user interface (what you see on the screen) and the network.
It intercepts all network requests and allows the application to decide how to handle each request.
You can pre-cache responses, fetch from the network and chose to cache the response on demand.
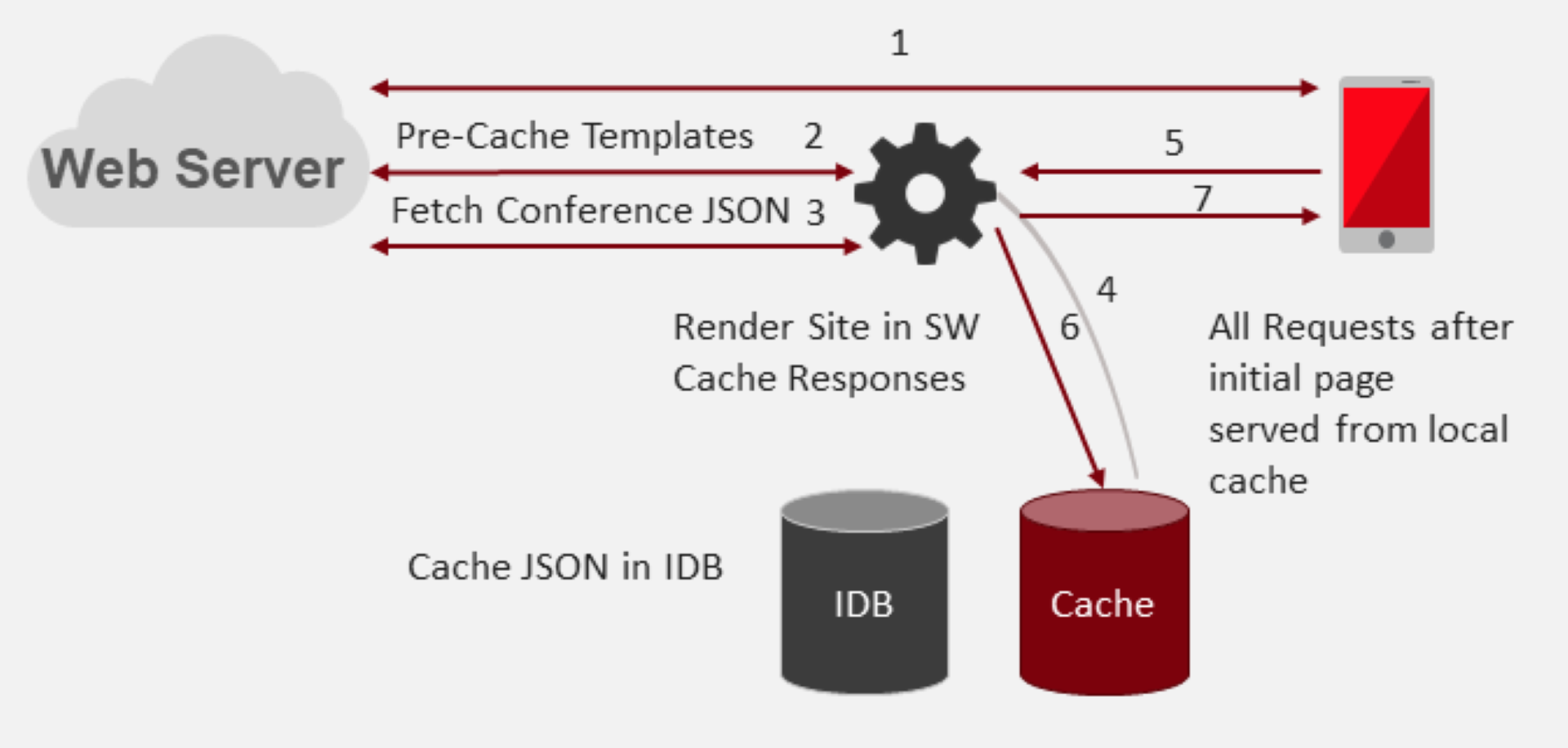
Caching in the context of a website is where something is stored either in memory on the server. In the case of a PWA, caching is done on the client device.
Common assets cached in a PWA include HTML, CSS, JavaScript, Images, Videos, Fonts and data.
Cached responses are returned from the local cache and the network request avoided. By storing application assets on the device the application can function in an offline state.
Anytime you eliminate a network request the UI can respond and render a little faster. But the bigger benefit is often reduced load on the server.
Just like a serverless backend can distribute processing a PWA can handle some processing. This distributes your application demand to the local device instead of the cloud.
Don't push everything to the client, just what is needed for a good user experience.
Summary
Government systems are not the only organizations relying on outdated technology. I see it all the time with clients and third parties I am asked to integrate modern experiences.
Part of the problem is software is looked at as a capital expense, like a fork lift. And that makes sense if you are an accountant. So depreciation logic applies and you look at software as a tool.
Objects like desks, vehicles, etc. have rather long life spans. A 1970's file cabinet works just as well today, despite a few dings, as it did 45 years ago.
Software does not last that long. It requires constant nurturing and upgrades.
The United States is not an isolated case. Countries all over the world are struggling with demand.
Australia's national broadband service has felt the strain.
"But experts argue the increased traffic is adding strain to a network not yet finished but already out of date by global standards. And while the network may still function, the current health crisis has laid bare the decrepit state of Australia’s broadband infrastructure."
The increase in online activity is world wide. It seems roughly a 25% increase in digital activity across the board. And instead of spiking on weekends, as was the normal trend it is more or less sustained.
Once social distancing is disbanded many, myself included, believe life will not revert to previous trends. Instead the rise in online activity will most likely remain.
Working from home will be a new normal for the majority. Online shopping will be in more demand than ever before.
Your business, government and organization need to handle the increased activity, not just respond to a sudden spike.
As a final word of advice. If thousands of online businesses can handle increased volume without service interruption there is no reason government services should go down.
Scaling problems are more or less solved. Your business and organization can take advantage of cloud based solutions. And the modern solutions are much cheaper than maintaining legacy platforms.
Don't let your application crash. Apply modern standards and scale while saving money. This creates a better user experience which creates happier customers.
Happy customers mean your business can thrive!




